If queries start to queue in a multi-cluster virtual warehouse, an additional compute cluster starts immediately under what setting?
Auto-scale mode
Maximized mode
Economy scaling policy
Standard scaling policy
In Snowflake, when queries begin to queue in a multi-cluster virtual warehouse, an additional compute cluster starts immediately if the warehouse is set to auto-scale mode. This mode allows Snowflake to automatically add or resume additional clusters as soon as the workload increases, and similarly, shut down or pause the additional clusters when the load decreases
Which privilege is required for a role to be able to resume a suspended warehouse if auto-resume is not enabled?
USAGE
OPERATE
MONITOR
MODIFY
The OPERATE privilege is required for a role to resume a suspended warehouse if auto-resume is not enabled. This privilege allows the role to start, stop, suspend, or resume a virtual warehouse3.
References: [COF-C02] SnowPro Core Certification Exam Study Guide
What action can a user take to address query concurrency issues?
Enable the query acceleration service.
Enable the search optimization service.
Add additional clusters to the virtual warehouse
Resize the virtual warehouse to a larger instance size.
To address query concurrency issues, a user can add additional clusters to the virtual warehouse. This allows for the distribution of queries across multiple clusters, reducing the load on any single cluster and improving overall query performance2.
How long does Snowflake retain information in the ACCESS HISTORY view?
7 days
14 days
28 days
365 days
Snowflake retains information in the ACCESS HISTORY view for 365 days. This allows users to query the access history of Snowflake objects within the last year1.
What is the name of the SnowSQLfile that can store connection information?
history
config
snowsqLcnf
snowsql.pubkey
The SnowSQL file that can store connection information is named ‘config’. It is used to store user credentials and connection details for easy access to Snowflake instances. References: Based on general database knowledge as of 2021.
Which statement MOST accurately describes clustering in Snowflake?
The database ACCOUNTADMIN must define the clustering methodology for each Snowflake table.
Clustering is the way data is grouped together and stored within Snowflake micro-partitions.
The clustering key must be included in the COPY command when loading data into Snowflake.
Clustering can be disabled within a Snowflake account.
Clustering in Snowflake refers to the organization of data within micro-partitions, which are contiguous units of storage within Snowflake tables. Clustering keys can be defined to co-locate similar rows in the same micro-partitions, improving scan efficiency and query performance12.
References: [COF-C02] SnowPro Core Certification Exam Study Guide
What statistical information in a Query Profile indicates that the query is too large to fit in memory? (Select TWO).
Bytes spilled to local cache.
Bytes spilled to local storage.
Bytes spilled to remote cache.
Bytes spilled to remote storage.
Bytes spilled to remote metastore.
In a Query Profile, the statistical information that indicates a query is too large to fit in memory includes bytes spilled to local cache and bytes spilled to local storage. These metrics suggest that the working data set of the query exceeded the memory available on the warehouse nodes, causing intermediate results to be written to disk
Which command is used to unload files from an internal or external stage to a local file system?
COPY INTO
GET
PUT
TRANSFER
The command used to unload files from an internal or external stage to a local file system in Snowflake is the GET command. This command allows users to download data files that have been staged, making them available on the local file system for further use23.
What can a Snowflake user do in the Admin area of Snowsight?
Analyze query performance.
Write queries and execute them.
Provide an overview of the listings in the Snowflake Marketplace.
Connect to Snowflake partners to explore extended functionality.
In the Admin area of Snowsight, users can analyze query performance, manage Snowflake warehouses, set up and view details about resource monitors, manage users and roles, and administer Snowflake accounts in their organization2.
Network policies can be applied to which of the following Snowflake objects? (Choose two.)
Roles
Databases
Warehouses
Users
Accounts
Network policies in Snowflake can be applied to users and accounts. These policies control inbound access to the Snowflake service and internal stages, allowing or denying access based on the originating network identifiers12.
References: [COF-C02] SnowPro Core Certification Exam Study Guide
What file formats does Snowflake support for loading semi-structured data? (Choose three.)
TSV
JSON
Avro
Parquet
JPEG
Snowflake supports several semi-structured data formats for loading data. The supported formats include JSON, Avro, and Parquet12. These formats allow for efficient storage and querying of data that does not conform to a traditional relational database schema.
Using variables in Snowflake is denoted by using which SQL character?
@
&
$
#
∗∗VeryComprehensiveExplanation=InSnowflake,variablesaredenotedbyadollarsign(). Variables can be used in SQL statements where a literal constant is allowed, and they must be prefixed with a $ sign to distinguish them from bind values and column names.
How can a data provider ensure that a data consumer is going to have access to the required objects?
Enable the data sharing feature in the account and validate the view.
Use the CURRENT_ROLE and CURRENT_USER functions to validate secure views.
Use the CURRENT_ function to authorize users from a specific account to access rows in a base table.
Set the SIMULATED DATA SHARING CONSUMER session parameter to the name of the consumer account for which access is being simulated.
To ensure a data consumer has access to the required objects, a data provider can enable the data sharing feature and validate that the consumer can access the views or tables shared with them. References: Based on general data sharing practices in cloud services as of 2021.
Which Snowflake tool would be BEST to troubleshoot network connectivity?
SnowCLI
SnowUI
SnowSQL
SnowCD
SnowCD (Snowflake Connectivity Diagnostic Tool) is the best tool provided by Snowflake for troubleshooting network connectivity issues. It helps diagnose and resolve issues related to connecting to Snowflake services
How can a user change which columns are referenced in a view?
Modify the columns in the underlying table
Use the ALTER VIEW command to update the view
Recreate the view with the required changes
Materialize the view to perform the changes
In Snowflake, to change the columns referenced in a view, the view must be recreated with the required changes. The ALTER VIEW command does not allow changing the definition of a view; it can only be used to rename a view, convert it to or from a secure view, or add, overwrite, or remove a comment for a view. Therefore, the correct approach is to drop the existing view and create a new one with the desired column references.
Which REST API can be used with unstructured data?
inscrtFilcs
insertReport
GET /api/tiles/
loadHistoryScan
The REST API used with unstructured data in Snowflake is GET /api/files/, which retrieves (downloads) a data file from an internal or external stage4.
Which parameter can be used to instruct a COPY command to verify data files instead of loading them into a specified table?
STRIP_NULL_VALUES
SKIP_BYTE_ORDER_MARK
REPLACE_INVALID_CHARACTERS
VALIDATION_MODE
The VALIDATION_MODE parameter can be used with the COPY command to verify data files without loading them into the specified table. This parameter allows users to check for errors in the files
A tabular User-Defined Function (UDF) is defined by specifying a return clause that contains which keyword?
ROW_NUMBER
TABLE
TABULAR
VALUES
In Snowflake, a tabular User-Defined Function (UDF) is defined with a return clause that includes the keyword “TABLE.” This indicates that the UDF will return a set of rows, which can be used in the FROM clause of a query. References: Based on my internal knowledge as of 2021.
Which file format will keep floating-point numbers from being truncated when data is unloaded?
CSV
JSON
ORC
Parquet
The Parquet file format is known for preserving the precision of floating-point numbers when data is unloaded, preventing truncation of the values3.
What are benefits of using Snowpark with Snowflake? (Select TWO).
Snowpark uses a Spark engine to generate optimized SQL query plans.
Snowpark automatically sets up Spark within Snowflake virtual warehouses.
Snowpark does not require that a separate cluster be running outside of Snowflake.
Snowpark allows users to run existing Spark code on virtual warehouses without the need to reconfigure the code.
Snowpark executes as much work as possible in the source databases for all operations including User-Defined Functions (UDFs).
Snowpark is designed to bring the data programmability to Snowflake, enabling developers to write code in familiar languages like Scala, Java, and Python. It allows for the execution of these codes directly within Snowflake’s virtual warehouses, eliminating the need for a separate cluster. Additionally, Snowpark’s compatibility with Spark allows users to leverage their existing Spark code with minimal changes1.
What is the minimum Snowflake edition needed for database failover and fail-back between Snowflake accounts for business continuity and disaster recovery?
Standard
Enterprise
Business Critical
Virtual Private Snowflake
The minimum Snowflake edition required for database failover and fail-back between Snowflake accounts for business continuity and disaster recovery is the Business Critical edition. References: Snowflake Documentation3.
When should a user consider disabling auto-suspend for a virtual warehouse? (Select TWO).
When users will be using compute at different times throughout a 24/7 period
When managing a steady workload
When the compute must be available with no delay or lag time
When the user does not want to have to manually turn on the warehouse each time it is needed
When the warehouse is shared across different teams
Disabling auto-suspend for a virtual warehouse is recommended when there is a steady workload, which ensures that compute resources are always available. Additionally, it is advisable to disable auto-suspend when immediate availability of compute resources is critical, eliminating any startup delay
Which of the following are considerations when using a directory table when working with unstructured data? (Choose two.)
A directory table is a separate database object.
Directory tables store data file metadata.
A directory table will be automatically added to a stage.
Directory tables do not have their own grantable privileges.
Directory table data can not be refreshed manually.
Directory tables in Snowflake are used to store metadata about data files in a stage. They are not separate database objects but are conceptually similar to external tables. Directory tables do not have grantable privileges of their own
What effect does WAIT_FOR_COMPLETION = TRUE have when running an ALTER WAREHOUSE command and changing the warehouse size?
The warehouse size does not change until all queries currently running in the warehouse have completed.
The warehouse size does not change until all queries currently in the warehouse queue have completed.
The warehouse size does not change until the warehouse is suspended and restarted.
It does not return from the command until the warehouse has finished changing its size.
The WAIT_FOR_COMPLETION = TRUE parameter in an ALTER WAREHOUSE command ensures that the command does not return until the warehouse has completed resizing. This means that the command will wait until all the necessary compute resources have been provisioned and the warehouse size has been changed. References: [COF-C02] SnowPro Core Certification Exam Study Guide
Two users share a virtual warehouse named wh dev 01. When one of the users loads data, the other one experiences performance issues while querying data.
How does Snowflake recommend resolving this issue?
Scale up the existing warehouse.
Create separate warehouses for each user.
Create separate warehouses for each workload.
Stop loading and querying data at the same time.
Snowflake recommends creating separate warehouses for each workload to resolve performance issues caused by shared virtual warehouses. This ensures that the resources are not being overutilized by one user’s activities, thereby affecting the performance of another user’s activities4.
Which database objects can be shared with the Snowflake secure data sharing feature? (Choose two.)
Files
External tables
Secure User-Defined Functions (UDFs)
Sequences
Streams
Snowflake’s secure data sharing feature allows sharing of certain database objects with other Snowflake accounts. Among the options provided, external tables and secure UDFs can be shared
What is used to diagnose and troubleshoot network connections to Snowflake?
SnowCD
Snowpark
Snowsight
SnowSQL
SnowCD (Snowflake Connectivity Diagnostic Tool) is used to diagnose and troubleshoot network connections to Snowflake. It runs a series of connection checks to evaluate the network connection to Snowflake
Which stages are used with the Snowflake PUT command to upload files from a local file system? (Choose three.)
Schema Stage
User Stage
Database Stage
Table Stage
External Named Stage
Internal Named Stage
The Snowflake PUT command is used to upload files from a local file system to Snowflake stages, specifically the user stage, table stage, and internal named stage. These stages are where the data files are temporarily stored before being loaded into Snowflake tables
When unloading data to an external stage, what is the MAXIMUM file size supported?
1 GB
5 GB
10 GB
16 GB
When unloading data to an external stage, the maximum file size supported is 5 GB. This limit ensures efficient data transfer and management within Snowflake’s architecture
Where is Snowflake metadata stored?
Within the data files
In the virtual warehouse layer
In the cloud services layer
In the remote storage layer
Snowflake’s architecture is divided into three layers: database storage, query processing, and cloud services. The metadata, which includes information about the structure of the data, the SQL operations performed, and the service-level policies, is stored in the cloud services layer. This layer acts as the brain of the Snowflake environment, managing metadata, query optimization, and transaction coordination.
What is the MAXIMUM size limit for a record of a VARIANT data type?
8MB
16MB
32MB
128MB
The maximum size limit for a record of a VARIANT data type in Snowflake is 16MB. This allows for storing semi-structured data types like JSON, Avro, ORC, Parquet, or XML within a single VARIANT column. References: Based on general database knowledge as of 2021.
A Snowflake user has two tables that contain numeric values and is trying to find out which values are present in both tables. Which set operator should be used?
INTERSECT
MFRCK
MINUS
UNION
To find out which numeric values are present in both tables, the INTERSECT set operator should be used. This operator returns rows from one query’s result set which also appear in another query’s result set, effectively finding the common elements between the two tables45.
Which Snowflake object can be accessed in he FROM clause of a query, returning a set of rows having one or more columns?
A User-Defined Table Function (UDTF)
A Scalar User Function (UDF)
A stored procedure
A task
In Snowflake, a User-Defined Table Function (UDTF) can be accessed in the FROM clause of a query. UDTFs return a set of rows with one or more columns, which can be queried like a regular table
A Snowflake user executed a query and received the results. Another user executed the same query 4 hours later. The data had not changed.
What will occur?
No virtual warehouse will be used, data will be read from the result cache.
No virtual warehouse will be used, data will be read from the local disk cache.
The default virtual warehouse will be used to read all data.
The virtual warehouse that is defined at the session level will be used to read all data.
Snowflake maintains a result cache that stores the results of every query for 24 hours. If the same query is executed again within this time frame and the data has not changed, Snowflake will retrieve the data from the result cache instead of using a virtual warehouse to recompute the results2.
A view is defined on a permanent table. A temporary table with the same name is created in the same schema as the referenced table. What will the query from the view return?
The data from the permanent table.
The data from the temporary table.
An error stating that the view could not be compiled.
An error stating that the referenced object could not be uniquely identified.
When a view is defined on a permanent table, and a temporary table with the same name is created in the same schema, the query from the view will return the data from the permanent table. Temporary tables are session-specific and do not affect the data returned by views defined on permanent tables2.
A user with which privileges can create or manage other users in a Snowflake account? (Select TWO).
GRANT
SELECT
MODIFY
OWNERSHIP
CREATE USER
A user with the OWNERSHIP privilege on a user object or the CREATE USER privilege on the account can create or manage other users in a Snowflake account56.
Which type of loop requires a BREAK statement to stop executing?
FOR
LOOP
REPEAT
WHILE
The LOOP type of loop in Snowflake Scripting does not have a built-in termination condition and requires a BREAK statement to stop executing4.
Which Snowflake function will parse a JSON-null into a SQL-null?
TO_CHAR
TO_VARIANT
TO_VARCHAR
STRIP NULL VALUE
The STRIP_NULL_VALUE function in Snowflake is used to convert a JSON null value into a SQL NULL value1.
How can a Snowflake administrator determine which user has accessed a database object that contains sensitive information?
Review the granted privileges to the database object.
Review the row access policy for the database object.
Query the ACCESS_HlSTORY view in the ACCOUNT_USAGE schema.
Query the REPLICATION USAGE HISTORY view in the ORGANIZATION USAGE schema.
To determine which user has accessed a database object containing sensitive information, a Snowflake administrator can query the ACCESS_HISTORY view in the ACCOUNT_USAGE schema, which provides information about access to database objects3.
How should clustering be used to optimize the performance of queries that run on a very large table?
Manually re-cluster the table regularly.
Choose one high cardinality column as the clustering key.
Use the column that is most-frequently used in query select clauses as the clustering key.
Assess the average table depth to identify how clustering is impacting the query.
For optimizing the performance of queries that run on a very large table, it is recommended to choose one high cardinality column as the clustering key. This helps to co-locate similar rows in the same micro-partitions, improving scan efficiency in queries by skipping data that does not match filtering predicates4.
References: [COF-C02] SnowPro Core Certification Exam Study Guide
Which commands can only be executed using SnowSQL? (Select TWO).
COPY INTO
GET
LIST
PUT
REMOVE
The LIST and PUT commands are specific to SnowSQL and cannot be executed in the web interface or other SQL clients. LIST is used to display the contents of a stage, and PUT is used to upload files to a stage. References: [COF-C02] SnowPro Core Certification Exam Study Guide
Which operation can be performed on Snowflake external tables?
INSERT
JOIN
RENAME
ALTER
Snowflake external tables are read-only, which means data manipulation language (DML) operations like INSERT, RENAME, or ALTER cannot be performed on them. However, external tables can be used for query and join operations3.
References: [COF-C02] SnowPro Core Certification Exam Study Guide
For which use cases is running a virtual warehouse required? (Select TWO).
When creating a table
When loading data into a table
When unloading data from a table
When executing a show command
When executing a list command
Running a virtual warehouse is required when loading data into a table and when unloading data from a table because these operations require compute resources that are provided by the virtual warehouse23.
Which Snowflake data types can be used to build nested hierarchical data? (Select TWO)
INTEGER
OBJECT
VARIANT
VARCHAR
LIST
The Snowflake data types that can be used to build nested hierarchical data are OBJECT and VARIANT. These data types support the storage and querying of semi-structured data, allowing for the creation of complex, nested data structures
How can a dropped internal stage be restored?
Enable Time Travel.
Clone the dropped stage.
Execute the UNDROP command.
Recreate the dropped stage.
Once an internal stage is dropped in Snowflake, it cannot be recovered or restored using Time Travel or UNDROP commands. The only option is to recreate the dropped stage
What does SnowCD help Snowflake users to do?
Copy data into files.
Manage different databases and schemas.
Troubleshoot network connections to Snowflake.
Write SELECT queries to retrieve data from external tables.
SnowCD is a connectivity diagnostic tool that helps users troubleshoot network connections to Snowflake. It performs a series of checks to evaluate the network connection and provides suggestions for resolving any issues4.
Which object can be used with Secure Data Sharing?
View
Materialized view
External table
User-Defined Function (UDF)
Views can be used with Secure Data Sharing in Snowflake. Materialized views, external tables, and UDFs are not typically shared directly for security and performance reasons2.
NO: 504
When enabling access to unstructured data, which URL permits temporary access to a staged file without the need to grant privileges to the stage or to issue access tokens?
File URL
Scoped URL
Relative URL
Pre-Signed URL
A Scoped URL permits temporary access to a staged file without the need to grant privileges to the stage or to issue access tokens. It provides a secure way to share access to files stored in Snowflake
What is the purpose of the STRIP NULL_VALUES file format option when loading semi-structured data files into Snowflake?
It removes null values from all columns in the data.
It converts null values to empty strings during loading.
It skips rows with null values during the loading process.
It removes object or array elements containing null values.
The STRIP NULL_VALUES file format option, when set to TRUE, removes object or array elements that contain null values during the loading process of semi-structured data files into Snowflake. This ensures that the data loaded into Snowflake tables does not contain these null elements, which can be useful when the “null” values in files indicate missing values and have no other special meaning2.
References: [COF-C02] SnowPro Core Certification Exam Study Guide
A JSON file, that contains lots of dates and arrays, needs to be processed in Snowflake. The user wants to ensure optimal performance while querying the data.
How can this be achieved?
Flatten the data and store it in structured data types in a flattened table. Query the table.
Store the data in a table with a variant data type. Query the table.
Store the data in a table with a vai : ant data type and include STRIP_NULL_VALUES while loading the table. Query the table.
Store the data in an external stage and create views on top of it. Query the views.
Storing JSON data in a table with a VARIANT data type is optimal for querying because it allows Snowflake to leverage its semi-structured data capabilities. This approach enables efficient storage and querying without the need for flattening the data, which can be performance-intensive1.
At what level is the MIN_DATA_RETENTION_TIME_IN_DAYS parameter set?
Account
Database
Schema
Table
The MIN_DATA_RETENTION_TIME_IN_DAYS parameter is set at the account level. This parameter determines the minimum number of days Snowflake retains historical data for Time Travel operations
What is a characteristic of materialized views in Snowflake?
Materialized views do not allow joins.
Clones of materialized views can be created directly by the user.
Multiple tables can be joined in the underlying query of a materialized view.
Aggregate functions can be used as window functions in materialized views.
One of the characteristics of materialized views in Snowflake is that they allow multiple tables to be joined in the underlying query. This enables the pre-computation of complex queries involving joins, which can significantly improve the performance of subsequent queries that access the materialized view4. References: [COF-C02] SnowPro Core Certification Exam Study Guide
What does the LATERAL modifier for the FLATTEN function do?
Casts the values of the flattened data
Extracts the path of the flattened data
Joins information outside the object with the flattened data
Retrieves a single instance of a repeating element in the flattened data
The LATERAL modifier for the FLATTEN function allows joining information outside the object (such as other columns in the source table) with the flattened data, creating a lateral view that correlates with the preceding tables in the FROM clause2345. References: [COF-C02] SnowPro Core Certification Exam Study Guide
Which VALIDATION_MODE value will return the errors across the files specified in a COPY command, including files that were partially loaded during an earlier load?
RETURN_-1_R0WS
RETURN_n_ROWS
RETURN_ERRORS
RETURN ALL ERRORS
The RETURN_ERRORS value in the VALIDATION_MODE option of the COPY command instructs Snowflake to validate the data files and return errors encountered across all specified files, including those that were partially loaded during an earlier load2. References: [COF-C02] SnowPro Core Certification Exam Study Guide
Which statements describe benefits of Snowflake's separation of compute and storage? (Select TWO).
The separation allows independent scaling of computing resources.
The separation ensures consistent data encryption across all virtual data warehouses.
The separation supports automatic conversion of semi-structured data into structured data for advanced data analysis.
Storage volume growth and compute usage growth can be tightly coupled.
Compute can be scaled up or down without the requirement to add more storage.
Snowflake’s architecture allows for the independent scaling of compute resources, meaning you can increase or decrease the computational power as needed without affecting storage. This separation also means that storage can grow independently of compute usage, allowing for more flexible and cost-effective data management.
What is a directory table in Snowflake?
A separate database object that is used to store file-level metadata
An object layered on a stage that is used to store file-level metadata
A database object with grantable privileges for unstructured data tasks
A Snowflake table specifically designed for storing unstructured files
A directory table in Snowflake is an object layered on a stage that is used to store file-level metadata. It is not a separate database object but is conceptually similar to an external table because it stores metadata about the data files in the stage5.
What will prevent unauthorized access to a Snowflake account from an unknown source?
Network policy
End-to-end encryption
Multi-Factor Authentication (MFA)
Role-Based Access Control (RBAC)
A network policy in Snowflake is used to restrict access to the Snowflake account from unauthorized or unknown sources. It allows administrators to specify allowed IP address ranges, thus preventing access from any IP addresses not listed in the policy1.
What step can reduce data spilling in Snowflake?
Using a larger virtual warehouse
Increasing the virtual warehouse maximum timeout limit
Increasing the amount of remote storage for the virtual warehouse
Using a common table expression (CTE) instead of a temporary table
To reduce data spilling in Snowflake, using a larger virtual warehouse is effective because it provides more memory and local disk space, which can accommodate larger data operations and minimize the need to spill data to disk or remote storage1. References: [COF-C02] SnowPro Core Certification Exam Study Guide
Which Snowflake feature allows a user to track sensitive data for compliance, discovery, protection, and resource usage?
Tags
Comments
Internal tokenization
Row access policies
Tags in Snowflake allow users to track sensitive data for compliance, discovery, protection, and resource usage. They enable the categorization and tracking of data, supporting compliance with privacy regulations678. References: [COF-C02] SnowPro Core Certification Exam Study Guide
Which Snowflake feature provides increased login security for users connecting to Snowflake that is powered by Duo Security service?
OAuth
Network policies
Single Sign-On (SSO)
Multi-Factor Authentication (MFA)
Multi-Factor Authentication (MFA) provides increased login security for users connecting to Snowflake. Snowflake’s MFA is powered by Duo Security service, which adds an additional layer of security during the login process.
Which Snowflake feature allows administrators to identify unused data that may be archived or deleted?
Access history
Data classification
Dynamic Data Masking
Object tagging
The Access History feature in Snowflake allows administrators to track data access patterns and identify unused data. This information can be used to make decisions about archiving or deleting data to optimize storage and reduce costs.
Which Snowflake database object can be used to track data changes made to table data?
Tag
Task
Stream
Stored procedure
A Stream object in Snowflake is used for change data capture (CDC), which records data manipulation language (DML) changes made to tables, including inserts, updates, and deletes3.
Who can activate and enforce a network policy for all users in a Snowflake account? (Select TWO).
A user with an USERADMIN or higher role
A user with a SECURITYADMIN or higher role
A role that has been granted the ATTACH POLICY privilege
A role that has the NETWORK_POLlCY account parameter set
A role that has the ownership of the network policy
In Snowflake, a user with the SECURITYADMIN role or higher can activate and enforce a network policy for all users in an account. Additionally, a role that has ownership of the network policy can also activate and enforce it
Which commands are restricted in owner's rights stored procedures? (Select TWO).
SHOW
MERGE
INSERT
DELETE
DESCRIBE
In owner’s rights stored procedures, certain commands are restricted to maintain security and integrity. The SHOW and DESCRIBE commands are limited because they can reveal metadata and structure information that may not be intended for all roles.
Which metadata table will store the storage utilization information even for dropped tables?
DATABASE_STORAGE_USAGE_HISTORY
TABLE_STORAGE_METRICS
STORAGE_DAILY_HISTORY
STAGE STORAGE USAGE HISTORY
The TABLE_STORAGE_METRICS metadata table stores the storage utilization information, including for tables that have been dropped but are still incurring storage costs2.
TION NO: 521
Who can grant object privileges in a regular schema?
Object owner
Schema owner
Database owner
SYSADMIN
In a regular schema within Snowflake, the object owner has the privilege to grant object privileges. The object owner is typically the role that created the object or to whom the ownership of the object has been transferred78.
References = [COF-C02] SnowPro Core Certification Exam Study Guide
What are the least privileges needed to view and modify resource monitors? (Select TWO).
SELECT
OWNERSHIP
MONITOR
MODIFY
USAGE
To view and modify resource monitors, the least privileges needed are MONITOR and MODIFY. These privileges allow a user to monitor credit usage and make changes to resource monitors3.
While working with unstructured data, which file function generates a Snowflake-hosted file URL to a staged file using the stage name and relative file path as inputs?
GET_PRESIGNED_URL
GET_ABSOLUTE_PATH
BUILD_STAGE_FILE_URL
BUILD SCOPED FILE URL
The BUILD_STAGE_FILE_URL function generates a Snowflake-hosted file URL to a staged file using the stage name and relative file path as inputs2.
Which Snowflake view is used to support compliance auditing?
ACCESS_HISTORY
COPY_HISTORY
QUERY_HISTORY
ROW ACCESS POLICIES
The ACCESS_HISTORY view in Snowflake is utilized to support compliance auditing. It provides detailed information on data access within Snowflake, including reads and writes by user queries. This view is essential for regulatory compliance auditing as it offers insights into the usage of tables and columns, and maintains a direct link between the user, the query, and the accessed data1.
References: [COF-C02] SnowPro Core Certification Exam Study Guide
When working with a managed access schema, who has the OWNERSHIP privilege of any tables added to the schema?
The database owner
The object owner
The schema owner
The Snowflake user's role
In a managed access schema, the schema owner retains the OWNERSHIP privilege of any tables added to the schema. This means that while object owners have certain privileges over the objects they create, only the schema owner can manage privilege grants on these objects1.
What happens to the objects in a reader account when the DROP MANAGED ACCOUNT command is executed?
The objects are dropped.
The objects enter the Fail-safe period.
The objects enter the Time Travel period.
The objects are immediately moved to the provider account.
When the DROP MANAGED ACCOUNT command is executed in Snowflake, it removes the managed account, including all objects created within the account, and access to the account is immediately restricted2.
References: [COF-C02] SnowPro Core Certification Exam Study Guide
What Snowflake feature provides a data hub for secure data collaboration, with a selected group of invited members?
Data Replication
Secure Data Sharing
Data Exchange
Snowflake Marketplace
Snowflake’s Data Exchange feature provides a data hub for secure data collaboration. It allows providers to publish data that can be discovered and accessed by a selected group of invited members, facilitating secure and controlled data sharing within a collaborative environment3. References: [COF-C02] SnowPro Core Certification Exam Study Guide
How can a Snowflake user validate data that is unloaded using the COPY INTO
Load the data into a CSV file.
Load the data into a relational table.
Use the VALlDATlON_MODE - SQL statement.
Use the validation mode = return rows statement.
To validate data unloaded using the COPY INTO
Which of the following commands cannot be used within a reader account?
CREATE SHARE
ALTER WAREHOUSE
DROP ROLE
SHOW SCHEMAS
DESCRBE TABLE
In Snowflake, a reader account is a type of account that is intended for consuming shared data rather than performing any data management or DDL operations. The CREATE SHARE command is used to share data from your account with another account, which is not a capability provided to reader accounts. Reader accounts are typically restricted from creating shares, as their primary purpose is to read shared data rather than to share it themselves.
References:
Snowflake Documentation on Reader Accounts
SnowPro® Core Certification Study Guide
The Information Schema and Account Usage Share provide storage information for which of the following objects? (Choose three.)
Users
Tables
Databases
Internal Stages
The Information Schema and Account Usage Share in Snowflake provide metadata and historical usage data for various objects within a Snowflake account. Specifically, they offer storage information for Tables, Databases, and Internal Stages. These schemas contain views and table functions that allow users to query object metadata and usage metrics, such as the amount of data stored and historical activity.
Tables: The storage information includes data on the daily average amount of data in database tables.
Databases: For databases, the storage usage is calculated based on all the data contained within the database, including tables and stages.
Internal Stages: Internal stages are locations within Snowflake for temporarily storing data, and their storage usage is also tracked.
References: The information is verified according to the SnowPro Core Certification Study Guide and Snowflake documentation
Which services does the Snowflake Cloud Services layer manage? (Select TWO).
Compute resources
Query execution
Authentication
Data storage
Metadata
The Snowflake Cloud Services layer manages a variety of services that are crucial for the operation of the Snowflake platform. Among these services, Authentication and Metadata management are key components. Authentication is essential for controlling access to the Snowflake environment, ensuring that only authorized users can perform actions within the platform. Metadata management involves handling all the metadata related to objects within Snowflake, such as tables, views, and databases, which is vital for the organization and retrieval of data.
References:
[COF-C02] SnowPro Core Certification Exam Study Guide
Snowflake Documentation12
https://docs.snowflake.com/en/user-guide/intro-key-concepts.html
Which command can be used to stage local files from which Snowflake interface?
SnowSQL
Snowflake classic web interface (Ul)
Snowsight
.NET driver
SnowSQL is the command-line client for Snowflake that allows users to execute SQL queries and perform all DDL and DML operations, including staging files for bulk data loading. It is specifically designed for scripting and automating tasks.
References:
SnowPro Core Certification Exam Study Guide
Snowflake Documentation on SnowSQL
https://docs.snowflake.com/en/user-guid e/snowsql-use.html
How would you determine the size of the virtual warehouse used for a task?
Root task may be executed concurrently (i.e. multiple instances), it is recommended to leave some margins in the execution window to avoid missing instances of execution
Querying (select) the size of the stream content would help determine the warehouse size. For example, if querying large stream content, use a larger warehouse size
If using the stored procedure to execute multiple SQL statements, it's best to test run the stored procedure separately to size the compute resource first
Since task infrastructure is based on running the task body on schedule, it's recommended to configure the virtual warehouse for automatic concurrency handling using Multi-cluster warehouse (MCW) to match the task schedule
The size of the virtual warehouse for a task can be configured to handle concurrency automatically using a Multi-cluster warehouse (MCW). This is because tasks are designed to run their body on a schedule, and MCW allows for scaling compute resources to match the task’s execution needs without manual intervention. References: [COF-C02] SnowPro Core Certification Exam Study Guide
True or False: Reader Accounts are able to extract data from shared data objects for use outside of Snowflake.
True
False
Reader accounts in Snowflake are designed to allow users to read data shared with them but do not have the capability to extract data for use outside of Snowflake. They are intended for consuming shared data within the Snowflake environment only.
Which of the following describes how clustering keys work in Snowflake?
Clustering keys update the micro-partitions in place with a full sort, and impact the DML operations.
Clustering keys sort the designated columns over time, without blocking DML operations
Clustering keys create a distributed, parallel data structure of pointers to a table's rows and columns
Clustering keys establish a hashed key on each node of a virtual warehouse to optimize joins at run-time
Clustering keys in Snowflake work by sorting the designated columns over time. This process is done in the background and does not block data manipulation language (DML) operations, allowing for normal database operations to continue without interruption. The purpose of clustering keys is to organize the data within micro-partitions to optimize query performance1.
References:
[COF-C02] SnowPro Core Certification Exam Study Guide
Snowflake Documentation on Clustering1
What is a limitation of a Materialized View?
A Materialized View cannot support any aggregate functions
A Materialized View can only reference up to two tables
A Materialized View cannot be joined with other tables
A Materialized View cannot be defined with a JOIN
Materialized Views in Snowflake are designed to store the result of a query and can be refreshed to maintain up-to-date data. However, they have certain limitations, one of which is that they cannot be defined using a JOIN clause. This means that a Materialized View can only be created based on a single source table and cannot combine data from multiple tables using JOIN operations.
References:
Snowflake Documentation on Materialized Views
SnowPro® Core Certification Study Guide
What happens to the underlying table data when a CLUSTER BY clause is added to a Snowflake table?
Data is hashed by the cluster key to facilitate fast searches for common data values
Larger micro-partitions are created for common data values to reduce the number of partitions that must be scanned
Smaller micro-partitions are created for common data values to allow for more parallelism
Data may be colocated by the cluster key within the micro-partitions to improve pruning performance
When a CLUSTER BY clause is added to a Snowflake table, it specifies one or more columns to organize the data within the table’s micro-partitions. This clustering aims to colocate data with similar values in the same or adjacent micro-partitions. By doing so, it enhances the efficiency of query pruning, where the Snowflake query optimizer can skip over irrelevant micro-partitions that do not contain the data relevant to the query, thereby improving performance.
References:
Snowflake Documentation on Clustering Keys & Clustered Tables1.
Community discussions on how source data’s ordering affects a table with a cluster key
How long is Snowpipe data load history retained?
As configured in the create pipe settings
Until the pipe is dropped
64 days
14 days
Snowpipe data load history is retained for 64 days. This retention period allows users to review and audit the data load operations performed by Snowpipe over a significant period of time, which can be crucial for troubleshooting and ensuring data integrity.
References:
[COF-C02] SnowPro Core Certification Exam Study Guide
Snowflake Documentation on Snowpipe1
When is the result set cache no longer available? (Select TWO)
When another warehouse is used to execute the query
When another user executes the query
When the underlying data has changed
When the warehouse used to execute the query is suspended
When it has been 24 hours since the last query
The result set cache in Snowflake is invalidated and no longer available when the underlying data of the query results has changed, ensuring that queries return the most current data. Additionally, the cache expires after 24 hours to maintain the efficiency and accuracy of data retrieval1.
Which statement about billing applies to Snowflake credits?
Credits are billed per-minute with a 60-minute minimum
Credits are used to pay for cloud data storage usage
Credits are consumed based on the number of credits billed for each hour that a warehouse runs
Credits are consumed based on the warehouse size and the time the warehouse is running
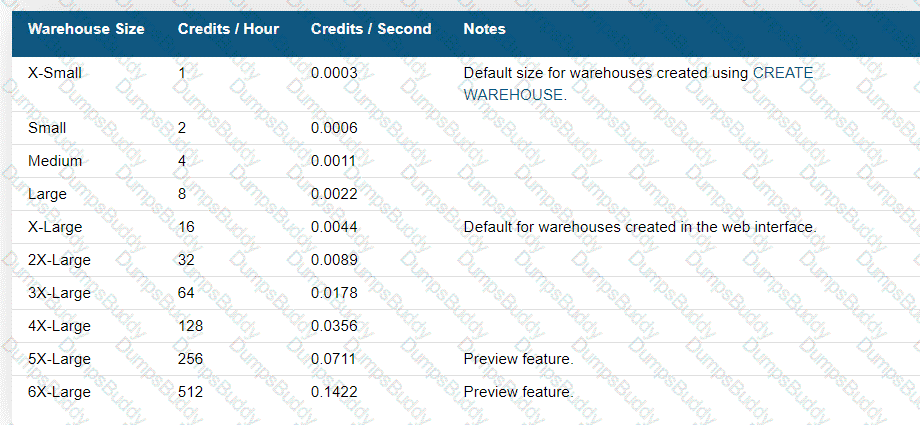
Snowflake credits are the unit of measure for the compute resources used in Snowflake. The number of credits consumed depends on the size of the virtual warehouse and the time it is running. Larger warehouses consume more credits per hour than smaller ones, and credits are billed for the time the warehouse is active, regardless of the actual usage within that time.
References: [COF-C02] SnowPro Core Certification Exam Study Guide
What are ways to create and manage data shares in Snowflake? (Select TWO)
Through the Snowflake web interface (Ul)
Through the DATA_SHARE=TRUE parameter
Through SQL commands
Through the enable__share=true parameter
Using the CREATE SHARE AS SELECT * TABLE command
Data shares in Snowflake can be created and managed through the Snowflake web interface, which provides a user-friendly graphical interface for various operations. Additionally, SQL commands can be used to perform these tasks programmatically, offering flexibility and automation capabilities123.
Which data type can be used to store geospatial data in Snowflake?
Variant
Object
Geometry
Geography
Snowflake supports two geospatial data types: GEOGRAPHY and GEOMETRY. The GEOGRAPHY data type is used to store geospatial data that models the Earth as a perfect sphere, which is suitable for global geospatial data. This data type follows the WGS 84 standard and is used for storing points, lines, and polygons on the Earth’s surface. The GEOMETRY data type, on the other hand, represents features in a planar (Euclidean, Cartesian) coordinate system and is typically used for local spatial reference systems. Since the question specifically asks about geospatial data, which commonly refers to Earth-related spatial data, the correct answer is GEOGRAPHY3. References: [COF-C02] SnowPro Core Certification Exam Study Guide
Which Snowflake objects track DML changes made to tables, like inserts, updates, and deletes?
Pipes
Streams
Tasks
D. Procedures
In Snowflake, Streams are the objects that track Data Manipulation Language (DML) changes made to tables, such as inserts, updates, and deletes. Streams record these changes along with metadata about each change, enabling actions to be taken using the changed data. This process is known as change data capture (CDC)2.
A user needs to create a materialized view in the schema MYDB.MYSCHEMA.
Which statements will provide this access?
GRANT ROLE MYROLE TO USER USER1;
CREATE MATERIALIZED VIEW ON SCHEMA MYDB.MYSCHEMA TO ROLE MYROLE;
GRANT ROLE MYROLE TO USER USER1;
CREATE MATERIALIZED VIEW ON SCHEMA MYDB.MYSCHEMA TO USER USER1;
GRANT ROLE MYROLE TO USER USER1;
CREATE MATERIALIZED VIEW ON SCHEMA MYDB.MYSCHEMA TO USER1;
GRANT ROLE MYROLE TO USER USER1;
CREATE MATERIALIZED VIEW ON SCHEMA MYDB.MYSCHEMA TO MYROLE;
In Snowflake, to create a materialized view, the user must have the necessary privileges on the schema where the view will be created. These privileges are granted through roles, not directly to individual users. Therefore, the correct process is to grant the role to the user and then grant the privilege to create the materialized view to the role itself.
The statement GRANT ROLE MYROLE TO USER USER1; grants the specified role to the user, allowing them to assume that role and exercise its privileges. The subsequent statement CREATE MATERIALIZED VIEW ON SCHEMA MYDB.MYSCHEMA TO MYROLE; grants the privilege to create a materialized view within the specified schema to the role MYROLE. Any user who has been granted MYROLE can then create materialized views in MYDB.MYSCHEMA.
References:
Snowflake Documentation on Roles
Snowflake Documentation on Materialized Views
Which of the following conditions must be met in order to return results from the results cache? (Select TWO).
The user has the appropriate privileges on the objects associated with the query
Micro-partitions have been reclustered since the query was last run
The new query is run using the same virtual warehouse as the previous query
The query includes a User Defined Function (UDF)
The query has been run within 24 hours of the previously-run query
To return results from the results cache in Snowflake, certain conditions must be met:
Privileges: The user must have the appropriate privileges on the objects associated with the query. This ensures that only authorized users can access cached data.
Time Frame: The query must have been run within 24 hours of the previously-run query. Snowflake’s results cache is designed to store the results of queries for a short period, typically 24 hours, to improve performance for repeated queries.
Which cache type is used to cache data output from SQL queries?
Metadata cache
Result cache
Remote cache
Local file cache
The Result cache is used in Snowflake to cache the data output from SQL queries. This feature is designed to improve performance by storing the results of queries for a period of time. When the same or similar query is executed again, Snowflake can retrieve the result from this cache instead of re-computing the result, which saves time and computational resources.
References:
Snowflake Documentation on Query Results Cache
SnowPro® Core Certification Study Guide
What is the default File Format used in the COPY command if one is not specified?
CSV
JSON
Parquet
XML
The default file format for the COPY command in Snowflake, when not specified, is CSV (Comma-Separated Values). This format is widely used for data exchange because it is simple, easy to read, and supported by many data analysis tools.
What can be used to view warehouse usage over time? (Select Two).
The load HISTORY view
The Query history view
The show warehouses command
The WAREHOUSE_METERING__HISTORY View
The billing and usage tab in the Snowflake web Ul
To view warehouse usage over time, the Query history view and the WAREHOUSE_METERING__HISTORY View can be utilized. The Query history view allows users to monitor the performance of their queries and the load on their warehouses over a specified period1. The WAREHOUSE_METERING__HISTORY View provides detailed information about the workload on a warehouse within a specified date range, including average running and queued loads2. References: [COF-C02] SnowPro Core Certification Exam Study Guide
A company strongly encourages all Snowflake users to self-enroll in Snowflake's default Multi-Factor Authentication (MFA) service to provide increased login security for users connecting to Snowflake.
Which application will the Snowflake users need to install on their devices in order to connect with MFA?
Okta Verify
Duo Mobile
Microsoft Authenticator
Google Authenticator
Snowflake’s default Multi-Factor Authentication (MFA) service is powered by Duo Security. Users are required to install the Duo Mobile application on their devices to use MFA for increased login security when connecting to Snowflake. This service is managed entirely by Snowflake, and users do not need to sign up separately with Duo1.
Which feature is only available in the Enterprise or higher editions of Snowflake?
Column-level security
SOC 2 type II certification
Multi-factor Authentication (MFA)
Object-level access control
Column-level security is a feature that allows fine-grained control over access to specific columns within a table. This is particularly useful for managing sensitive data and ensuring that only authorized users can view or manipulate certain pieces of information. According to my last update, this feature was available in the Enterprise Edition or higher editions of Snowflake.
References: Based on my internal data as of 2021, column-level security is an advanced feature typically reserved for higher-tiered editions like the Enterprise Edition in data warehousing solutions such as Snowflake.
https://docs.sn owflake.com/en/user-guide/intro-editions.html
What is the MOST performant file format for loading data in Snowflake?
CSV (Unzipped)
Parquet
CSV (Gzipped)
ORC
Parquet is a columnar storage file format that is optimized for performance in Snowflake. It is designed to be efficient for both storage and query performance, particularly for complex queries on large datasets. Parquet files support efficient compression and encoding schemes, which can lead to significant savings in storage and speed in query processing, making it the most performant file format for loading data into Snowflake.
References:
[COF-C02] SnowPro Core Certification Exam Study Guide
Snowflake Documentation on Data Loading1
A user is loading JSON documents composed of a huge array containing multiple records into Snowflake. The user enables the strip__outer_array file format option
What does the STRIP_OUTER_ARRAY file format do?
It removes the last element of the outer array.
It removes the outer array structure and loads the records into separate table rows,
It removes the trailing spaces in the last element of the outer array and loads the records into separate table columns
It removes the NULL elements from the JSON object eliminating invalid data and enables the ability to load the records
The STRIP_OUTER_ARRAY file format option in Snowflake is used when loading JSON documents that are composed of a large array containing multiple records. When this option is enabled, it removes the outer array structure, which allows each record within the array to be loaded as a separate row in the table. This is particularly useful for efficiently loading JSON data that is structured as an array of records1.
References:
Snowflake Documentation on JSON File Format
[COF-C02] SnowPro Core Certification Exam Study Guide
Which semi-structured file formats are supported when unloading data from a table? (Select TWO).
ORC
XML
Avro
Parquet
JSON
Semi-structured
JSON, Parquet
Snowflake supports unloading data in several semi-structured file formats, including Parquet and JSON. These formats allow for efficient storage and querying of semi-structured data, which can be loaded directly into Snowflake tables without requiring a predefined schema12.
https://docs.snowflake.com/en/user-guide/data-unload-prepare.html#:~:text=Supported%20File%20Formats,-The%20following%20file &text=Delimited%20(CSV%2C%20TSV%2C%20etc.)
A user has 10 files in a stage containing new customer data. The ingest operation completes with no errors, using the following command:
COPY INTO my__table FROM @my__stage;
The next day the user adds 10 files to the stage so that now the stage contains a mixture of new customer data and updates to the previous data. The user did not remove the 10 original files.
If the user runs the same copy into command what will happen?
All data from all of the files on the stage will be appended to the table
Only data about new customers from the new files will be appended to the table
The operation will fail with the error uncertain files in stage.
All data from only the newly-added files will be appended to the table.
When the COPY INTO command is executed in Snowflake, it processes all files present in the specified stage that have not been ingested before or marked as already loaded. Since the user did not remove the original 10 files after the first load, running the same COPY INTO command again will result in all 20 files being processed. This means that the data from the original 10 files will be appended to the table again, along with the data from the new 10 files, potentially leading to duplicate records for the original data set.
References:
Snowflake Documentation on Data Loading
SnowPro® Core Certification Study Guide
What are two ways to create and manage Data Shares in Snowflake? (Choose two.)
Via the Snowflake Web Interface (Ul)
Via the data_share=true parameter
Via SQL commands
Via Virtual Warehouses
In Snowflake, Data Shares can be created and managed in two primary ways:
Via the Snowflake Web Interface (UI): Users can create and manage shares through the graphical interface provided by Snowflake, which allows for a user-friendly experience.
Via SQL commands: Snowflake also allows the creation and management of shares using SQL commands. This method is more suited for users who prefer scripting or need to automate the process.
What features does Snowflake Time Travel enable?
Querying data-related objects that were created within the past 365 days
Restoring data-related objects that have been deleted within the past 90 days
Conducting point-in-time analysis for Bl reporting
Analyzing data usage/manipulation over all periods of time
Snowflake Time Travel is a powerful feature that allows users to access historical data within a defined period. It enables two key capabilities:
B. Restoring data-related objects that have been deleted within the past 90 days: Time Travel can be used to restore tables, schemas, and databases that have been accidentally or intentionally deleted within the Time Travel retention period.
C. Conducting point-in-time analysis for BI reporting: It allows users to query historical data as it appeared at a specific point in time within the Time Travel retention period, which is crucial for business intelligence and reporting purposes.
While Time Travel does allow querying of past data, it is limited to the retention period set for the Snowflake account, which is typically 1 day for standard accounts and can be extended up to 90 days for enterprise accounts. It does not enable querying or restoring objects created or deleted beyond the retention period, nor does it provide analysis over all periods of time.
References:
Snowflake Documentation on Time Travel
SnowPro® Core Certification Study Guide
Which Snowflake object enables loading data from files as soon as they are available in a cloud storage location?
Pipe
External stage
Task
Stream
In Snowflake, a Pipe is the object designed to enable the continuous, near-real-time loading of data from files as soon as they are available in a cloud storage location. Pipes use Snowflake’s COPY command to load data and can be associated with a Stage object to monitor for new files. When new data files appear in the stage, the pipe automatically loads the data into the target table.
References:
Snowflake Documentation on Pipes
SnowPro® Core Certification Study Guide
https://docs.snowflake.com/en/user-guide/data-load-snowpipe-intro.html
What Snowflake role must be granted for a user to create and manage accounts?
ACCOUNTADMIN
ORGADMIN
SECURITYADMIN
SYSADMIN
The ACCOUNTADMIN role is required for a user to create and manage accounts in Snowflake. This role has the highest level of privileges and is responsible for managing all aspects of the Snowflake account, including the ability to create and manage other user accounts1.
https://docs.snowflake.com/en/user-guide/security-access-control-considerations.html
True or False: A 4X-Large Warehouse may, at times, take longer to provision than a X-Small Warehouse.
True
False
Provisioning time can vary based on the size of the warehouse. A 4X-Large Warehouse typically has more resources and may take longer to provision compared to a X-Small Warehouse, which has fewer resources and can generally be provisioned more quickly.References: Understanding and viewing Fail-safe | Snowflake Documentation
What tasks can be completed using the copy command? (Select TWO)
Columns can be aggregated
Columns can be joined with an existing table
Columns can be reordered
Columns can be omitted
Data can be loaded without the need to spin up a virtual warehouse
The COPY command in Snowflake allows for the reordering of columns as they are loaded into a table, and it also permits the omission of columns from the source file during the load process. This provides flexibility in handling the schema of the data being ingested. References: [COF-C02] SnowPro Core Certification Exam Study Guide
In the query profiler view for a query, which components represent areas that can be used to help optimize query performance? (Select TWO)
Bytes scanned
Bytes sent over the network
Number of partitions scanned
Percentage scanned from cache
External bytes scanned
In the query profiler view, the components that represent areas that can be used to help optimize query performance include ‘Bytes scanned’ and ‘Number of partitions scanned’. ‘Bytes scanned’ indicates the total amount of data the query had to read and is a direct indicator of the query’s efficiency. Reducing the bytes scanned can lead to lower data transfer costs and faster query execution. ‘Number of partitions scanned’ reflects how well the data is clustered; fewer partitions scanned typically means better performance because the system can skip irrelevant data more effectively.
References:
[COF-C02] SnowPro Core Certification Exam Study Guide
Snowflake Documentation on Query Profiling1
What is the purpose of an External Function?
To call code that executes outside of Snowflake
To run a function in another Snowflake database
To share data in Snowflake with external parties
To ingest data from on-premises data sources
The purpose of an External Function in Snowflake is to call code that executes outside of the Snowflake environment. This allows Snowflake to interact with external services and leverage functionalities that are not natively available within Snowflake, such as calling APIs or running custom code hosted on cloud services3.
https://docs.snowflake.com/en/sql-reference/external-functions.html
Which is the MINIMUM required Snowflake edition that a user must have if they want to use AWS/Azure Privatelink or Google Cloud Private Service Connect?
Standard
Premium
Enterprise
Business Critical
A user has an application that writes a new Tile to a cloud storage location every 5 minutes.
What would be the MOST efficient way to get the files into Snowflake?
Create a task that runs a copy into operation from an external stage every 5 minutes
Create a task that puts the files in an internal stage and automate the data loading wizard
Create a task that runs a GET operation to intermittently check for new files
Set up cloud provider notifications on the Tile location and use Snowpipe with auto-ingest
The most efficient way to get files into Snowflake, especially when new files are being written to a cloud storage location at frequent intervals, is to use Snowpipe with auto-ingest. Snowpipe is Snowflake’s continuous data ingestion service that loads data as soon as it becomes available in a cloud storage location. By setting up cloud provider notifications, Snowpipe can be triggered automatically whenever new files are written to the storage location, ensuring that the data is loaded into Snowflake with minimal latency and without the need for manual intervention or scheduling frequent tasks.
References:
Snowflake Documentation on Snowpipe
SnowPro® Core Certification Study Guide
When reviewing the load for a warehouse using the load monitoring chart, the chart indicates that a high volume of Queries are always queuing in the warehouse
According to recommended best practice, what should be done to reduce the Queue volume? (Select TWO).
Use multi-clustered warehousing to scale out warehouse capacity.
Scale up the warehouse size to allow Queries to execute faster.
Stop and start the warehouse to clear the queued queries
Migrate some queries to a new warehouse to reduce load
Limit user access to the warehouse so fewer queries are run against it.
To address a high volume of queries queuing in a warehouse, Snowflake recommends two best practices:
A. Use multi-clustered warehousing to scale out warehouse capacity: This approach allows for the distribution of queries across multiple clusters within a warehouse, effectively managing the load and reducing the queue volume.
B. Scale up the warehouse size to allow Queries to execute faster: Increasing the size of the warehouse provides more compute resources, which can reduce the time it takes for queries to execute and thus decrease the number of queries waiting in the queue.
These strategies help to optimize the performance of the warehouse by ensuring that resources are scaled appropriately to meet demand.
References:
Snowflake Documentation on Multi-Cluster Warehousing
SnowPro Core Certification best practices
Which type of URL gives permanent access to files in cloud storage?
Pre-signed URL
Account URL
Scoped URL
File URL
A Snowflake table that is loaded using a Kafka connector has a schema consisting of which two variant columns? (Select TWO).
RECORD_TIMESTAMP
RECORD_CONTENT
RECORDKEY
RECORD_SESSION
RECORD_METADATA
When using the Snowflake Kafka connector, the table schema includes two important variant columns:
RECORD_TIMESTAMP: This column stores the timestamp from the Kafka record, enabling time-based analysis of incoming data.
RECORDKEY: This captures the unique key of each Kafka message, useful for uniquely identifying records or managing deduplication.
These columns ensure that each message’s metadata and key information are preserved, facilitating data analysis and real-time processing tasks in Snowflake.
How should a Snowflake use' configure a virtual warehouse to be in Maximized mode''
Set the WAREHOUSES_SIZE to 6XL.
Set the STATEMENT_TIMEOUT_1M_SECOMES to 0.
Set the MAX_CONCURRENCY_LEVEL to a value of 12 or large.
Set the same value for both MIN_CLUSTER_COUNT and MAX_CLUSTER_COUNT.
In Snowflake, configuring a virtual warehouse to be in a "Maximized" mode implies maximizing the resources allocated to the warehouse for its duration. This is done to ensure that the warehouse has a consistent amount of compute resources available, enhancing performance for workloads that require a high level of parallel processing or for handling high query volumes.
To configure a virtual warehouse in maximized mode, you should set the same value for both MIN_CLUSTER_COUNT and MAX_CLUSTER_COUNT. This configuration ensures that the warehouse operates with a fixed number of clusters, thereby providing a stable and maximized level of compute resources.
Reference to Snowflake documentation on warehouse sizing and scaling:
Warehouse Sizing and Scaling
Understanding Warehouses
What are the default Time Travel and Fail-safe retention periods for transient tables?
Time Travel - 1 day. Fail-safe - 1 day
Time Travel - 0 days. Fail-safe - 1 day
Time Travel - 1 day. Fail-safe - 0 days
Transient tables are retained in neither Fail-safe nor Time Travel
Transient tables in Snowflake have a default Time Travel retention period of 1 day, which allows users to access historical data within the last 24 hours. However, transient tables do not have a Fail-safe period. Fail-safe is an additional layer of data protection that retains data beyond the Time Travel period for recovery purposes in case of extreme data loss. Since transient tables are designed for temporary or intermediate workloads with no requirement for long-term durability, they do not include a Fail-safe period by default1.
References:
Snowflake Documentation on Storage Costs for Time Travel and Fail-safe
How can the outer array structure of a semi-structured file be removed?
Use the parameter strip_outer_array = true in a COPY INTO